
Web Development Nuts And Bolts: How to Publish a Website
Affiliate disclosure: Some of the links on this page are affiliate links, which means I may receive a commission if you decide to buy a product or service I have recommended. But if you’d prefer I didn’t receive a commission, that’s cool too. Just Google the vendor’s site instead of using my link. 🙂
It’s a great time to be a web developer.
There’s so many options, so many frameworks, so many places to learn.
But for a new developer, it can be tricky to see how it all fits together. How do you actually get from the thing you’ve been learning to something on the web that real people can use?
Maybe you’ve been reading all these great articles on React or Vue. Or maybe you’ve been learning HTML and CSS from freeCodeCamp. Or maybe you’ve been playing around with WordPress to set up your very own blog…
You’ve been working with it on your computer, you are able to get stuff to happen. But how do you get from working on stuff on your computer to a website everyone can see?
How do you actually publish this project as a website?
Don’t worry, you’re not alone in feeling stumped. There’s a lot of different pieces that go into making the web work, and it’s not always easy to see how they fit together.
This article aims to fill exactly that gap: starting from playing around with a website on your laptop, what are the things you need to know to get it live on the internet. It is aimed at beginners, so if you’re an expert feel free to scroll on by, and if you’re confused about anything scroll down and leave a comment. No question is too basic.
Let’s start from the user side - what actually happens when you browse the web?
Browsers
As a user your experience of the web is pretty much exclusively through the browser.
A web browser acts as combination document renderer + switchboard operator.
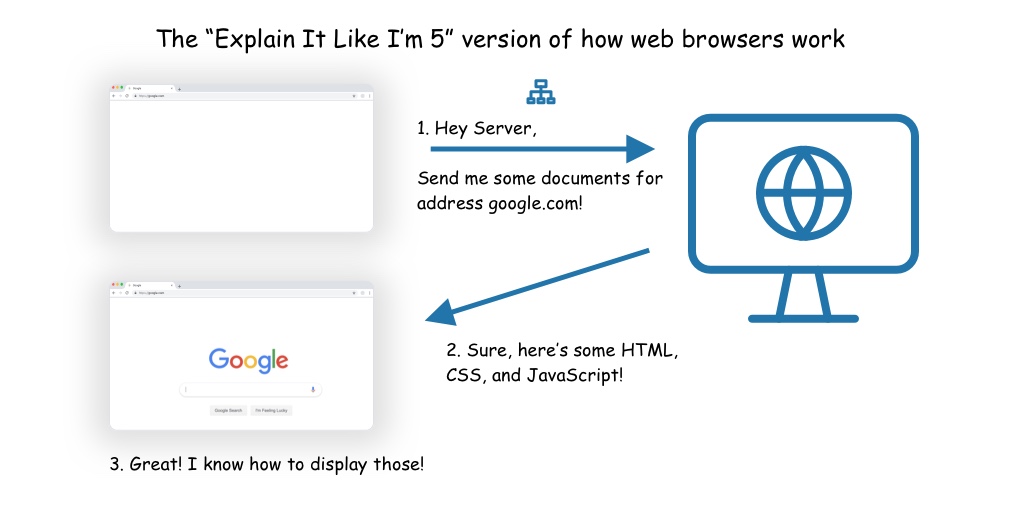
Document Renderer
As a model for a document renderer, think about something like Microsoft Word. Word takes a document in a particular format (“a word document”), and lets you view and interact with that document.
Browsers do exactly the same thing, but the formats they understand come in three major formats: HTML, CSS, and JavaScript. So instead of interpreting a “word document”, they interpret “an HTML document”, along with some associated “CSS documents” and “JavaScript documents”, and let you view and interact with them.
Going one step further, what the browser does is translate the HTML document into a set of objects called “Document Object Model” nodes, or DOM nodes. These form the basis of what you will see and interact with. CSS then can influence how those DOM nodes actually show up in the page, and JavaScript can dynamically add, take away, or manipulate those nodes based on its internal logic and user interaction.
Thus your browser, as a document renderer, translates a set of documents into an interactive page or application.
Switchboard Operator
The other thing that a browser does, and what makes the web magical, is it operates as a switchboard operator to go out and find the exact documents that it will render.
When you type a web address (aka URL) into your browser’s address bar (say for example https://zendev.com/friday-frontend.html, the address for my newsletter), the browser translates it into a request that it will send off to a webserver (computer) running somewhere on the web. It figures out from the domain (zendev.com) which server to send it to, and from the protocol and path (https and /friday-frontend.html respectively) what type of request to send.
That request is what will eventually result in the browser having a new set of documents to render, which brings us to the next key piece of our puzzle: What webservers are and how they work.
Webserver
A webserver is a program that knows how to respond to the types of requests your browser sends (HTTP or HTTPS), with content for that browser (for our purposes right now, HTML, CSS, or JavaScript). Some common webservers you may have heard of are Apache and Nginx.
Of course, browsers can (and do) ask for other things… images, videos, and many types of data formats… but for now lets limit our discussion to HTML, CSS, and JavaScript.
When a request comes in, the webserver sees what that request looks like - hey, someone is asking for /friday-frontend.html, and has to decide how to respond to it.
Static Content
The simplest possibility is if it already has a copy of that page exactly. This is how my website works, and generally is what is referred to as a “static” site.
Static means the webserver doesn’t do anything to change the content based on the request… it just maps straight from the request to an existing file and passes that file along as the response.
It’s also helpful to notice that different files can be treated differently. Most CSS and JavaScript files are served statically, which is why they are commonly referred to as ‘static assets’.
You write the code, perhaps do some transformations on it ahead of time using something like autoprefixer or a JavaScript build system, but by the time the webserver learns about them they are just files and aren’t going to be changed.
Dynamic Content
The next way that a webserver might respond with HTML is dynamically. This means that there is no file that holds exactly the HTML document that is going to be returned - instead the server will execute some logic (and often look up data from a database or something similar) and use that to create the HTML document that is going to be returned.
For example, if we were creating a user profile page, and we wanted to locate those pages in a predictable way, for example /users/kball and /users/coolcat. Each user’s profile would contain some information about that user, possibly stored in a database. Instead of creating actual html pages for kball and coolcat, we could use a dynamic server that recognized all routes of form /users/[:username], looked up data from a database based on the username, and rendered that data into a template to create the final HTML.
What about JavaScript frameworks?
Many developers today learn about JavaScript frameworks like React.js, Angular, or Vue.js as their first introduction to the web. How do they fit in?
First let’s step back a moment and highlight what JavaScript does for us on the web.
JavaScript’s Original Role
JavaScript is the primary language of interactivity on the web. You can use JavaScript to change and manipulate what a user sees without having to do another trip off to a server to get new content.
Want to show a modal when a user clicks something? You’ll probably use JavaScript to do that. Want to update only one part of the page without loading a whole new one? JavaScript again.
You can even fetch new data or pages from servers directly with JavaScript, letting you load new content without fully loading a new page. This approach, referred to broadly as AJAX has been used more and more because it allows for silky-smooth interactions and less time spent waiting for new pages.
In the extreme case, you get what is called a “Single Page Application” or “SPA”, where your initial HTML is just a shell that loads JavaScript, and the JavaScript does all the heavy lifting of setting out pages, fetching data, and even navigating between “pages” within the application.
Modern JavaScript frameworks
Modern JavaScript frameworks like React are taking this trend to its extreme. They give extremely powerful ways to control every piece of HTML in a page using JavaScript, and extremely developer-friendly abstractions and tooling for creating advanced applications easily.
Since JavaScript can now run on servers as well, many applications will even do what is called “server side rendering” or “universal JavaScript”, where you build essentially a single page application, but it is able to render all of its part either on a server (on that first page load) or in your web browser (for subsequent interactions)
These JavaScript applications then take responsibility for generating all of the HTML, and often all of the CSS in your application. They may load data from APIs or simply be a fancier way to generate static pages.
What are these APIs?
As more and more of web development has moved to JavaScript, more and more data and other functionality has begun to be exposed by APIs. There are many forms these can take, but a quick way of thinking of them is they are also webservers that handle dynamic content (just like we covered before for dynamic HTML), but instead of returning HTML they return a different form of document designed for JavaScript (or other programming languages) to read. This might be an XML document, or most commonly today a JSON document.
These API “endpoints” (a fancy name for a URL that accesses a particular API) can also handle all sorts of different operations - from saving data to processing credit cards, and everything in between.
Businesses like Stripe (for handling credit cards) or Auth0 (user authentication) will typically expose their products entirely as APIs, and then write custom “SDKs” (software development kits) for different programming languages (like JavaScript) that handle all the details of communicating with those APIs. To get started using them, you simply include their SDK in your website, add some account information specific to your account, and you’re off and running.
Putting it together
The final thing to understand to start piecing together how this works is that each HTML document (and to a lesser extent CSS and JavaScript documents) can reference other documents, which the browser will then pull in.
For example, an HTML document will typically reference some number of CSS and JavaScript documents that it needs in order to function. When your browser fetches that HTML page, as it starts to parse it in order to render it, it will see those dependencies and go off an get them.
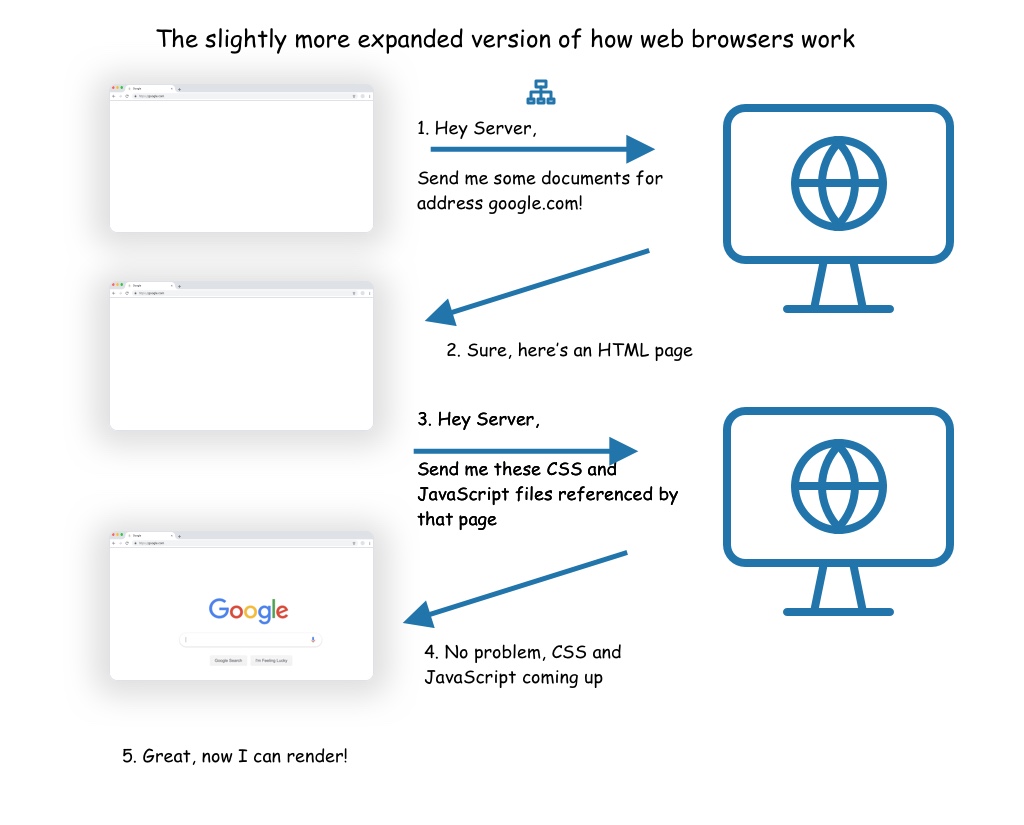
In the case of an application built with a JavaScript framework, there may be a set of additional AJAX calls to fetch more data and finish building out the page.
Once it is rendered, the user can interact with it, and you’re off and running. Clicking on links or submitting forms will start the cycle again with a new request.
So what does this mean in terms of creating our web projects and getting them visible on the web?
Finding a server, AKA hosting
First off, this means that no matter what you’re building, if you want it to be loadable by users there will need to be a webserver involved somewhere.
In many cases, companies will handle this for you. If you host a website on WordPress.com, or SquareSpace, or something similar those companies are the ones handling the webserver.
Similarly, there are a myriad of WordPress hosting companies that will let you “self host”, giving more control than the prepackaged solutions like WordPress.com, but will still take care of setting up a server to run WordPress. I’m not an expert in this, but WordPress.org (who are very much the experts here) recommend Bluehost, Dreamhost, and Siteground.
If you’re trying to find a way to host a fully static website, your options are much broader… you can use GitHub pages, Amazon S3, Netlify, or pretty much any other service that lets you make files accessible on the web.
Where it starts to get a little more complicated is if you’re trying to build something a little more custom or dynamic, using a dynamic webserver like Express (JavaScript), Django (python), or Ruby on Rails.
For these too, there are hosting solutions customized to their use, but you’re probably looking at either taking on a higher technical burden or paying for some more expensive handholding. Probably the simplest place to start is Heroku, which handles an awful lot of the technical burden/operations for you, but gets expensive as you start to scale up.
DNS – bare basics of domain names
One key item we didn’t cover was how a browser actually does it’s address lookup. When you type https://zendev.com/friday-frontend.html, how does it know that for zendev.com it needs to go to my server to make its request?
The system that manages this is called DNS - I’m not going to go into too much detail about it in this article, but at a high level you need to either purchase a domain name or piggy-back off of someone else’s domain.
Piggy-backing off of someone else’s is like if I had a website at https://WordPress.com/zendev or https://zendev.squarespace.com. It’s typically tied deeply into a more managed service, and is definitely not great from a branding perspective, but can be fine as you’re working on getting your site set up.
For getting your own domain, you’ll need to purchase one via a domain registrar and set it up to point to your webserver.
In terms of registrars, I highly recommend Hover. I’ve switched all my domains over to them, and don’t even look at other registries anymore.
In terms of setting up the domain to point to your webserver, that tends to be very specific to your hosting, particularly when using more managed services, so you should look at your hosting provider’s documentation. If you have trouble figuring it out, feel free to leave me a comment below and I’ll help point you in the right direction.
Hooking everything up
Once you’ve identified where you’re hosting your website or application, the next question is how do you actually get your files in place?
The “old school” approach is to find a way to “just put the files in place”. This relies on a convention - where do the files need to be? This varies by hosting provider, but it’s extremely common for there to be a “magic file directory” such as /var/www where the files will automatically be served by a webserver.
If this is the case for your provider, typically they will suggest a way to upload files to that location such as FTP. Even setting things up yourself, a “just get the files in place” solution can often be simplest. For my website zendev.com, I run a webserver called nginx that simply serves files from a particular directory. When I make an update, I just scp the files into that directory, and the changes show up.
The next most common way of pushing out code today is probably a source-control triggered deploy.
The word “deploy” is used to describe a discrete update of a set of things, and even if you’re using a “just put the files in place” approach, I recommend grouping changes into a deploy and tracking when you do updates.
Github pages are built from a git repository, where you configure if the pages should be served from the master branch, the gh-pages branch, or a /docs folder in the master branch. After configuration, any push to the mentioned branch will deploy an update.
Similarly, applications hosted on Heroku deploy based on pushes to a git repository.
Additional deployment approaches include things like packaging up docker images and more.
Wrapping Up
This article is intended to give you a big picture understanding of how web applications actually get from a development environment into something that real people can access and use. If there’s anything along the way that still feels unclear, please don’t hesitate to ask in the comments below.